Image-based methods have a history of being used to acquire performances, deformations, and animations that are inefficient to simulate in real-time or to model phenomena that are hard to model geometrically (e.g., view-dependent effects, complex foliage geometry). Non-rigid deformations, such as deforming cloth, fall into this category of being hard to model geometrically (e.g., due to folds, complex appearance) and are inefficient to physically simulate. Such non-rigid deformations can often be modeled as being dependent on the kinematic pose of a subject, meaning they can be effectively modeled using data-based methods. In this thesis, an image-based approach is used to acquire a compact model of such non-rigid deformation allowing the complex geometry and appearance effects to be transferred and rendered under novel animations and viewpoint.
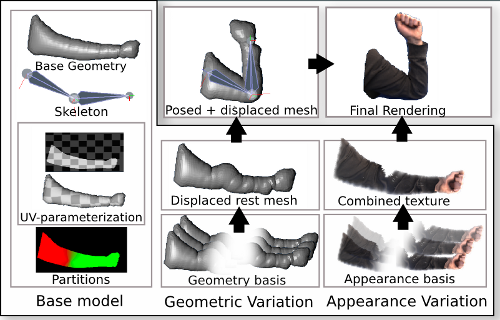
The compact model of non-rigid deformations is distilled from a multi-view training sequence that exhibits the desired pose-dependent deformations (e.g., bending of an arm). The observed geometric deformations are modeled with a pose-dependent geometry layered on top of a base geometry attached to a kinematic skeleton, and the appearance effects are modeled with a pose- and view-dependent appearance basis. Modeling appearance as pose- dependent allows it to model non-rigid effects (e.g., cloth shifting) that are not encoded in the geometry, while view-dependency allows the appearance to compensate for inaccurate geometries and specular effects. The model can then be used to efficiently synthesize and render the rich non-rigid deformations from novel viewpoints of the target object undergoing novel animation.
The vision-based acquisition pipeline for such a model consists of three main phases: acquiring a coarse base geometry, tracking the coarse motion of the base geometry, and obtaining fine scale deformations and correspondences of the surface through the training sequence.

For building the coarse base geometry of human subjects, a two camera turntable-based acquisition is proposed. The acquisition uses an interleaved tracking and silhouette refinement procedure to account for unintentional motion of the subject, while allowing the integration of silhouette cues throughout the turntable sequence. Tracking is shown to improve the geometric reconstruction, and multi-band blending is demonstrated to outperform weighted texture blending and super-resolution for obtaining a single texture map.
In order to track the joint angles through the training sequence, a common formulation for linear blend skinned meshes is used. The energy formulation combines several data terms (silhouette or intensity-based) with pose prior and smoothness terms. Local optimization is used for efficiency, and the different data energies are accelerated with the GPU, where intensity-based terms can achieve near-real time results but are fragile. Pose priors are shown to help when inputs are noisy, and exclusive-or-based silhouette energies are slower than iterative-closest-point schemes but outperform them when silhouettes are noisy.
The final component of acquisition, recovering the fine-scale geometric deformations, is studied in capture situations with a few or non-overlapping views. The simple case of a moving monocular camera is analyzed, where it is shown that the use of a simple constant velocity constraint enables the reconstruction of both dense scene flow and structure in a variational formulation. This restricted problem is then generalized to recovering dense flow on the surface of a moving base mesh, where a variational formulation is used to acquire long range flow in terms of a temporal motion basis. The temporal basis regularizes the reconstruction in time and allows for recovery of dense flow from non-overlapping views when the proxy motion undergoes enough motion.
The complete compact model is then demonstrated on several real examples, including modeling of cloth deformation on arms, transferring the appearance of wrinkles on pants to novel walk cycles, and applications of free-viewpoint compression. The experiments identify several key guidelines for both acquisition and modeling. Most importantly, the camera acquisition setup should take into account the viewpoint and illumination that are desired at render time, the input sequence should be designed such that the same pose is not observed multiple times, and the interpolation method should be based on the input pose and view configuration.
This site contains videos and supplementary material for my thesis. The site is not meant to be self contained, please see the main document or related publications.